Learning View Priors for Single-view 3D Reconstruction
CVPR 2019


Highlights
- The first work to enhance single-shot 3D reconstruction using image priors.
- An adversarial learning framework for acquiring image priors.
Abstract
There is some ambiguity in the 3D shape of an object when the number of observed views is small. Because of this ambiguity, although a 3D object reconstructor can be trained using a single view or a few views per object, reconstructed shapes only fit the observed views and appear incorrect from the unobserved viewpoints. To reconstruct shapes that look reasonable from any viewpoint, we propose to train a discriminator that learns prior knowledge regarding possible views. The discriminator is trained to distinguish the reconstructed views of the observed viewpoints from those of the unobserved viewpoints. The reconstructor is trained to correct unobserved views by fooling the discriminator. Our method outperforms current state-of-the-art methods on both synthetic and natural image datasets; this validates the effectiveness of our method.
Results
Single-view training on ShapeNet dataset
The ShapeNet dataset [1] consists of images synthetically generated from 3D CAD models.
In this experiment, we used a single view per object to train a 3D reconstructor. The following table shows the reconstruction accuracy (IoU). The only difference between our proposed method and the baseline is the use of view prior learning (VPL). Our method significantly improves performance.
| airplane | bench | dresser | car | chair | display | lamp | speaker | rifle | sofa | table | phone | vessel | mean | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Baseline (w/o texture) | .479 | .266 | .466 | .550 | .367 | .265 | .454 | .524 | .382 | .367 | .342 | .337 | .439 | .403 |
| Proposed (w/o texture) | .513 | .376 | .591 | .701 | .444 | .425 | .422 | .596 | .479 | .500 | .436 | .595 | .485 | .505 |
| Baseline (w/ texture) | .483 | .284 | .544 | .535 | .356 | .372 | .443 | .534 | .386 | .370 | .361 | .529 | .448 | .434 |
| Proposed (w/ texture) | .531 | .385 | .591 | .701 | .454 | .423 | .441 | .570 | .521 | .508 | .444 | .601 | .498 | .513 |
The three largest categories in the ShapeNet dataset are airplane, car, and chair.
| Input image | Baseline | Proposed | |
|---|---|---|---|
 |  |  | |
 |  |  | |
| | |
Our method is particularly effective for display and phone objects due to the significant shape ambiguity caused by their simple silhouettes.
| Input image | Baseline | Proposed | |
|---|---|---|---|
 |  |  | |
|  |  | |
 |  |  | |
|  |  |
Our method is also effective for sofa and bench because learning their elongated shapes from a single view—without considering multiple viewpoints—is challenging.
| Input image | Baseline | Proposed | |
|---|---|---|---|
 |  |  | |
|  | | |
 |  |  | |
|  |  |
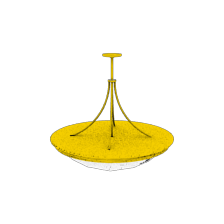
Multi-view training on ShapeNet dataset
Our method is also effective when multiple views per object are available for training. The table below shows the mean reconstruction accuracy on the ShapeNet dataset, with our approach consistently outperforming the baseline.
| Number of views per object | 2 | 3 | 5 | 10 | 20 |
|---|---|---|---|---|---|
| Baseline | .573 | .596 | .620 | .641 | .653 |
| Proposed | .583 | .600 | .624 | .644 | .655 |
When twenty views per object are used during training, our proposed method achieves state-of-the-art performance on the ShapeNet dataset.
| Method | Reconstruction accuracy (IoU) | |
|---|---|---|
| Multi-view training | PTN [2] | .574 |
| NMR [3] | .602 | |
| Our best model | .655 | |
| 3D supervision | 3D-R2N2 [4] | .560 |
| OGN [5] | .596 | |
| LSM [6] | .615 | |
| PSGN [7] | .640 | |
| VTN [8] | .641 |
| Input image | Proposed w/o texture | Proposed w/ texture | |
|---|---|---|---|
 |  |  | |
 |  |  | |
 |  |  | |
 |  |  | |
 |  |  | |
 |  |  | |
 |  |  | |
 |  |  | |
 |  |  | |
 |  |  | |
 |  |  | |
|  |  | |
 |  |  |
Single-view training on the PASCAL dataset
The PASCAL dataset [9] consists of natural images with noisy annotations. Our method achieves state-of-the-art performance on this challenging dataset.
| airplane | car | chair | mean | ||
|---|---|---|---|---|---|
| Category-agnostic models | DRC [10] | .415 | .666 | .247 | .443 |
| Baseline | .440 | .640 | .280 | .454 | |
| Proposed | .460 | .662 | .296 | .473 | |
| Category-specific models | CSDM [11] | .398 | .600 | .291 | .429 |
| CMR [12] | .46 | .64 | n/a | n/a | |
| Baseline | .450 | .669 | .293 | .470 | |
| Proposed | .475 | .679 | .304 | .486 |
| Input image | Baseline | Proposed | |
|---|---|---|---|
 |  |  | |
 |  |  | |
 |  |  | |
 |  |  | |
 | 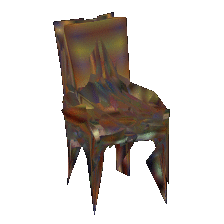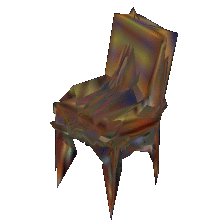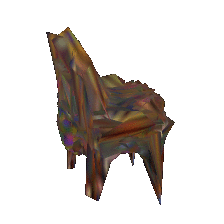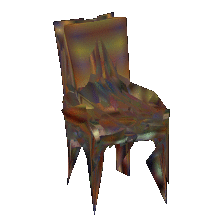 |  | |
 | 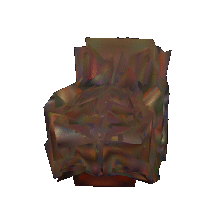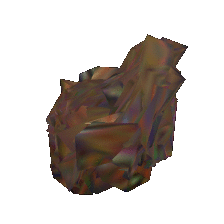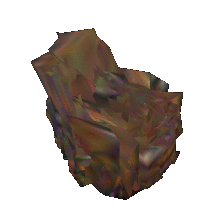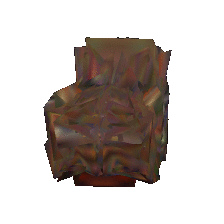 |  |
Technical overview
The following figure shows reconstruction results of a conventional method.
| Input | (A) Original View | (B) Unobserved Views |
|---|---|---|
|  |    |
 | 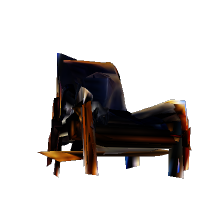 |  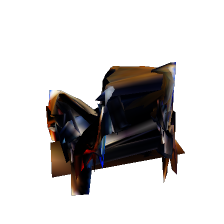 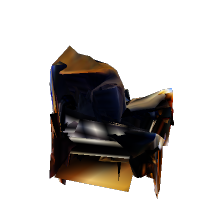 |
|  |    |
As shown in the figure, although reconstructed views from the original viewpoints (class A) appear correct, those from other viewpoints (class B) are inaccurate. We introduce a discriminator that distinguishes class A views from class B views. During training, this discriminator learns prior knowledge of realistic views. The reconstructor is then trained to generate correct unobserved views by fooling the discriminator, resulting in reconstructed shapes that appear reasonable from any viewpoint.
More details can be found in the paper.
References
- A. Chang et al. "Shapenet: An information-rich 3d model repository." arXiv. 2015.
- X. Yan et al. "Perspective Transformer Nets: Learning Single-view 3D Object Reconstruction without 3D Supervision." NIPS. 2016.
- H. Kato et al. "Neural 3D Mesh Renderer." CVPR. 2018.
- C. Choy et al. "3d-r2n2: A unified approach for single and multi-view 3d object reconstruction." ECCV. 2016.
- M. Tatarchenko et al. "Octree generating networks: Efficient convolutional architectures for high-resolution 3d outputs." ICCV. 2017.
- A. Kar et al. "Learning a multi-view stereo machine." NIPS. 2017.
- H. Fan et al. "A Point Set Generation Network for 3D Object Reconstruction from a Single Image." CVPR. 2017.
- S. Richter et al. "Matryoshka Networks: Predicting 3D Geometry via Nested Shape Layers." CVPR. 2018.
- Y. Xiang et al. "Beyond pascal: A benchmark for 3d object detection in the wild." WACV. 2014.
- S. Tulsiani et al. "Multi-view supervision for single-view reconstruction via differentiable ray consistency." CVPR. 2017.
- A. Kar et al. "Category-specific object reconstruction from a single image." CVPR. 2015.
- A. Kanazawa et al. "Learning Category-Specific Mesh Reconstruction from Image Collections." ECCV. 2018.
Citation
@InProceedings{kato2019vpl,
title={Learning View Priors for Single-view 3D Reconstruction},
author={Hiroharu Kato and Tatsuya Harada},
booktitle={The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2019}
}
Relevant Projects


powered by Academic Project Page Template